Web crawler là gì?
Web crawler là chương trình tự động do các công cụ tìm kiếm vận hành, có nhiệm vụ thu thập dữ liệu từ các trang web đang tồn tại trên môi trường internet.
Thông qua việc truy cập, quét và ghi nhận nội dung trên các trang World Wide Web, web crawler giúp công cụ tìm kiếm hiểu được cấu trúc, nội dung và mức độ liên quan của từng website. Nói một cách đơn giản, web crawler chính là “bot” của công cụ tìm kiếm, chịu trách nhiệm thu thập và lập chỉ mục (index) dữ liệu website.

Dựa trên dữ liệu do web crawler thu thập, công cụ tìm kiếm có thể phản hồi nhanh chóng các truy vấn của người dùng. Những thông tin phù hợp nhất sẽ được tổng hợp, sắp xếp và hiển thị dưới dạng danh sách kết quả, kèm theo đường dẫn gốc để người dùng dễ dàng truy cập. Toàn bộ quá trình thu thập và xử lý dữ liệu này được gọi là web crawling.
Cách thức hoạt động của Web Crawler
Để hiểu rõ bản chất và vai trò của web crawler, cần nắm được quy trình hoạt động cơ bản của công cụ này trong hệ sinh thái công cụ tìm kiếm.
Trước hết, web crawler sẽ truy cập và quét từng URL trên internet, đồng thời phân tích nội dung để phân loại các trang web có cùng chủ đề vào những nhóm liên quan. Trong quá trình này, các siêu liên kết (internal link và external link) trên mỗi website sẽ được thu thập và đưa vào danh sách các URL tiếp theo cần crawl.
Tiếp theo, web crawler đánh giá mức độ hữu ích và chất lượng của từng trang dựa trên nhiều chỉ số khác nhau như: lượt truy cập, số lượng và chất lượng backlinks, mức độ nhận diện thương hiệu, cấu trúc nội dung… Từ các dữ liệu này, công cụ tìm kiếm sẽ xác định trang nào cần được ưu tiên thu thập dữ liệu trước, cũng như tần suất crawl phù hợp.
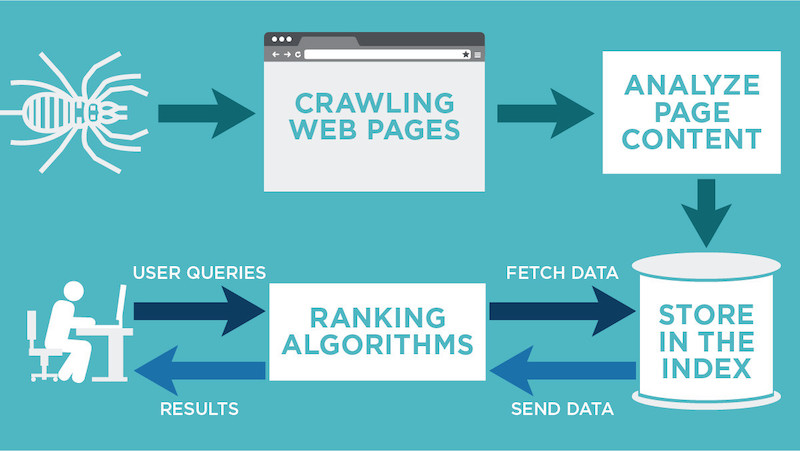
Sau đó, web crawler tiến hành kiểm tra các yếu tố kỹ thuật và nội dung SEO trên website, bao gồm thẻ meta, nội dung văn bản, dữ liệu đã lưu trữ và cấu trúc trang. Đồng thời, tệp robots.txt cũng được xem xét nhằm xác định những khu vực được phép hoặc không được phép thu thập thông tin, từ đó phục vụ quá trình lập chỉ mục (index).
Khi quá trình thu thập dữ liệu hoàn tất, công cụ tìm kiếm sẽ đánh giá khả năng hiển thị của trang web trên trang kết quả tìm kiếm (SERPs) khi người dùng thực hiện truy vấn liên quan.
Để web crawler thu thập dữ liệu một cách đầy đủ và chính xác, doanh nghiệp nên kết hợp các kỹ thuật tối ưu SEO cùng việc sử dụng phần mềm hỗ trợ phân tích website, qua đó cải thiện cấu trúc trang, nội dung và hiệu suất tổng thể của website.
Những yếu tố ảnh hưởng trực tiếp đến web crawler là gì?
Trong nhiều trường hợp, website đã được web crawler thu thập dữ liệu nhưng vẫn không xuất hiện trên trang kết quả tìm kiếm. Nguyên nhân đến từ việc một số yếu tố quan trọng chưa được tối ưu đúng cách. Dưới đây là những yếu tố tác động trực tiếp đến quá trình đánh giá và xếp hạng website của web crawler.
1. Tên miền
Tên miền không chỉ giúp người dùng nhận diện và truy cập website dễ dàng mà còn là một trong những căn cứ quan trọng để web crawler đánh giá mức độ liên quan của trang web. Tên miền nên được xây dựng theo định hướng SEO, có chứa từ khóa chính hoặc thể hiện rõ lĩnh vực, nội dung mà website đang cung cấp. Khi tên miền được tối ưu đúng chuẩn, website sẽ có nhiều cơ hội hơn để được web crawler ghi nhận và hiển thị trên trang kết quả tìm kiếm (SERPs).
2. Hệ thống backlinks
Backlinks là yếu tố thể hiện mức độ uy tín và ảnh hưởng của website trên môi trường internet. Dù nội dung được đầu tư chất lượng, website vẫn cần có các backlink tốt, đến từ những nguồn đáng tin cậy. Web crawler sẽ dựa vào số lượng và chất lượng backlinks để đánh giá mức độ tin cậy của website, từ đó ảnh hưởng trực tiếp đến khả năng xếp hạng.
3. Chất lượng nội dung
Nội dung trùng lặp là một trong những vấn đề khiến website bị đánh giá thấp. Web crawler sẽ so sánh thời điểm index để xác định đâu là nội dung gốc, đâu là nội dung sao chép.
Trong nhiều trường hợp, lỗi trùng lặp có thể phát sinh ngoài ý muốn, vì vậy việc thường xuyên kiểm tra, rà soát và xử lý kịp thời là rất cần thiết. Nếu không khắc phục, web crawler có thể lấy đây làm căn cứ để giảm mức độ ưu tiên và thứ hạng của website trên công cụ tìm kiếm.
4. Internal link – Liên kết nội bộ
Internal link có vai trò kết nối nội dung giữa các trang, bài viết trên cùng một website. Việc xây dựng hệ thống liên kết nội bộ hợp lý giúp giảm tỷ lệ thoát trang, cải thiện chỉ số time on site, tăng khả năng giữ chân người dùng và điều hướng khách hàng về đúng trang đích theo mục tiêu kinh doanh.

Để đạt hiệu quả, doanh nghiệp nên thường xuyên phân tích website nhằm xác định những trang cần bổ sung hoặc tối ưu thêm liên kết nội bộ.
Một lưu ý quan trọng là mỗi liên kết nội bộ nên gắn với một anchor text cụ thể, rõ nghĩa và liên quan trực tiếp đến nội dung trang đích. Cách làm này không chỉ thân thiện với người dùng mà còn giúp công cụ tìm kiếm hiểu rõ hơn về cấu trúc và chủ đề của website.
5. URL Canonical
Chuẩn SEO không chỉ dừng lại ở nội dung, liên kết nội bộ, backlink hay tên miền, mà còn thể hiện ở cách xây dựng URL. Việc sử dụng thẻ canonical giúp Google xác định chính xác đâu là phiên bản nội dung gốc trong trường hợp có nhiều URL trùng hoặc gần trùng nhau. Nhờ đó, website tránh được tình trạng trùng lặp nội dung và hỗ trợ quá trình thu thập, đánh giá dữ liệu của Google bot diễn ra hiệu quả hơn.
6. XML Sitemap
XML sitemap là thành phần không thể thiếu đối với bất kỳ website nào. Sitemap giúp Google bot nắm được danh sách toàn bộ các trang cần lập chỉ mục, từ đó dễ dàng truy cập, kiểm tra và đánh giá chất lượng website. Đặc biệt, khi website có sự thay đổi về cấu trúc hoặc nội dung, sitemap sẽ hỗ trợ quá trình crawl dữ liệu diễn ra nhanh chóng và chính xác hơn.

Trên đây là những thông tin cơ bản giúp giải đáp web crawler là gì cũng như vai trò của web crawler đối với website trong quá trình tối ưu SEO.
Hy vọng bài viết đã mang đến cho bạn góc nhìn rõ ràng và hữu ích. VicoGroup hân hạnh đồng hành cùng bạn trong các bài viết tiếp theo về kiến thức website và digital marketing.





